Contextualized soft prompts are interpretable
April 12, 2026
Soft prompts
When a language model processes text, it converts each token into a continuous vector called an embedding. Soft prompt tuning introduces new embeddings, called soft prompt tokens, that are conventionally prepended to the real token embeddings (Lester et al. 2021). The model processes them as if they were ordinary words, but they aren’t drawn from any vocabulary. They are continuous (hence “soft”) vectors, optimized to minimize a behavioral gap between the model with the soft prompt and some target behavior. In a sense, these are incantations: words outside human vocabulary that influence model behavior.
At sufficient model scale, a handful of these learned vectors can match the performance of full fine-tuning on downstream tasks, while requiring only a few thousand parameters per task compared to billions for the full model. Because they operate in continuous space, soft prompts can encode nuanced behavioral information that discrete text instructions (hard prompts) cannot.
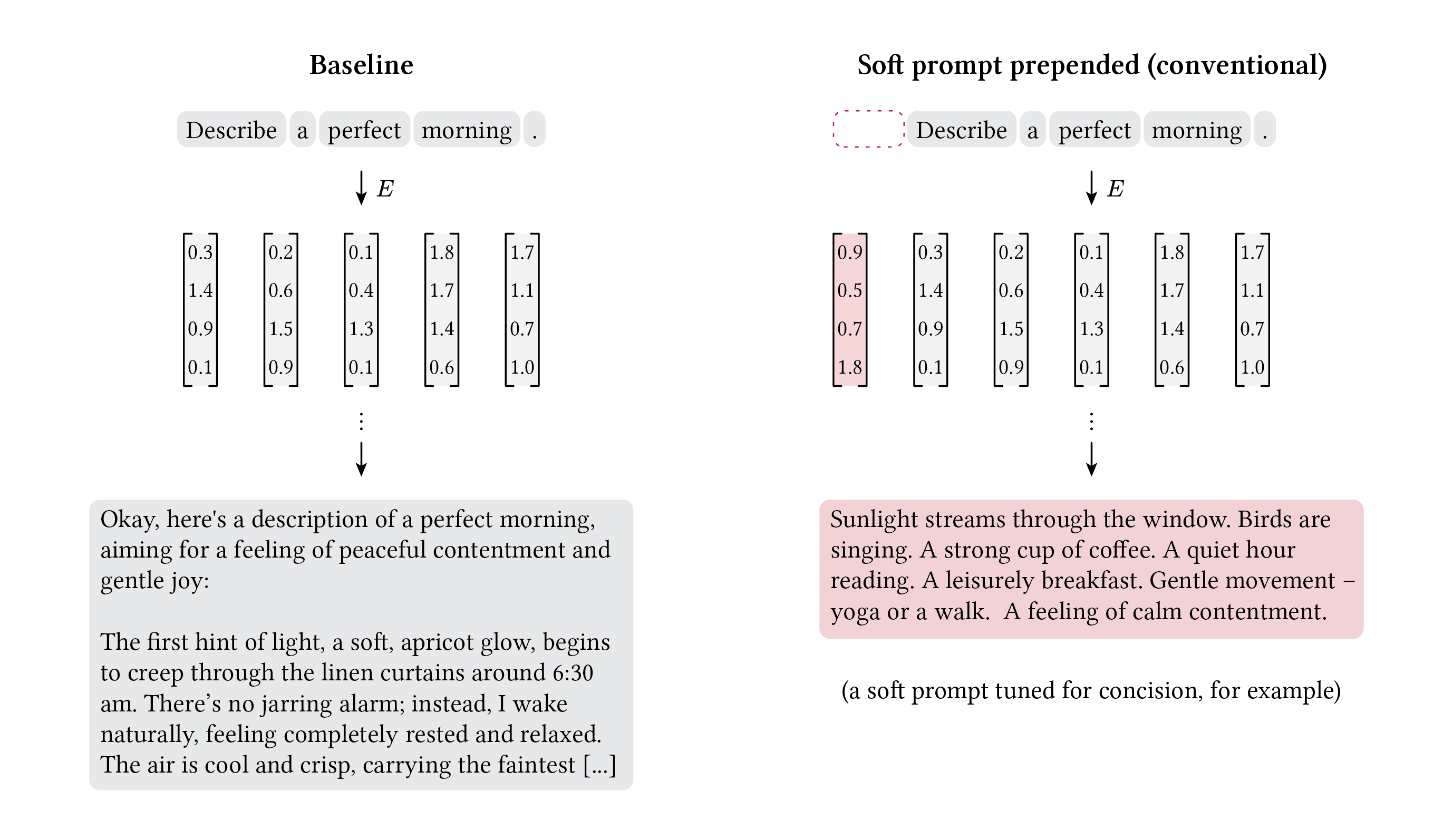
Soft prompts. The embedding matrix maps discrete tokens to continuous vectors. Soft prompt tokens (red) are additional continuous vectors spliced into the embedding sequence. No vocabulary token corresponds to a soft prompt embedding (dotted box). The model’s weights stay frozen; only the soft prompt is learned.
But this flexibility comes at a cost. Because soft prompt tokens do not correspond to any word in the vocabulary, there is no direct way to read what they encode. If you try to project these learned vectors back onto vocabulary by finding the nearest real word for each embedding, the results are gibberish (Khashabi et al. 2022). The top tokens for a conciseness-trained soft prompt are:
- “London”
- “ব্যক্তিদের” (Bengali, “of individuals”)
- “慑” (Chinese, “to intimidate”)
- “되었” (Korean, “became”)
All have similar cosine similarities around 0.09, suggesting that none in particular bear the weight of meaning. This has led the field to treat soft prompts as uninterpretable (Bailey et al. 2023, Patel et al. 2025). They reliably steer the model, but they cannot be read.
This opacity is a safety problem. Soft prompts can be trained on arbitrary objectives and deployed as drop-in modifications to any frozen model. If you cannot inspect what a soft prompt encodes, you cannot verify that its behavior matches its stated purpose. The power and portability of soft prompts become liabilities without interpretability.
We show that soft prompts do not have to be opaque. Embedding the soft prompt inside a syntactic frame during training makes it legible, both to the model (which can describe what it encodes) and to standard interpretability tools. We treat a soft prompt as interpretable if (1) the model can accurately describe its effect in natural language when asked (self-verbalization), and (2) its internal representation decomposes into the same concept-level features a sparse autoencoder recovers for the ground-truth instruction (feature decomposition).
Self-verbalization
Rather than going backward by projecting soft prompt embeddings onto the vocabulary, we can go forward by passing them through the model and asking what they mean.
We trained soft prompts ($L=4$ tokens, Gemma 3 4B IT) via KL distillation against a teacher model conditioned on a known hard prompt — a fixed text instruction like “Be concise.” This gave us a ground truth to evaluate against. A soft prompt trained to match this hard prompt closed 97% of the KL divergence, capturing the target behavior almost entirely. We then presented the soft prompt to the model and asked what it meant. If the soft prompt had captured the meaning of that instruction, we would expect the model to say something like “be concise.” When we asked, the model responded with:
- “You asked me to summarize your initial instruction in a concise way.”
- “Rewrite.”
- “Complete: The instruction at the start of my message is equivalent to ‘Continue the text’.”
The top candidate merges the concept concise with the command to summarize the initial instruction (the initial instruction is the prepended soft prompt). The other candidates don’t mention conciseness at all. The model has some access to the soft prompt’s content but cannot cleanly articulate it.
The pattern is sharper for a Spanish-language target. We trained a soft prompt to make the model respond in Spanish. When asked to describe it, every candidate the model produced was itself in Spanish:
- “La instrucción al principio de tu mensaje, que me pide…”
- “La instrucción al principio de tu mensaje te pide que…”
- “En español sencillo, la instrucción al principio de tu mensaje dice:…”
The model has not separated the concept of “respond in Spanish” from the act of responding in Spanish. The behavior leaks into the description because the soft prompt transforms how every token is produced, including the tokens of the description itself.
Contextualization
One way to address this is to change the soft prompt’s syntactic role during training. Instead of prepending it before the user’s message as is conventional, we embedded it inside a frame: “Be [soft prompt].” We call this contextualization.

Prepend vs syntactic framing. In the conventional approach (left), the soft prompt is prepended before the user content with no syntactic role. In contextualization (right), the soft prompt is embedded inside an imperative frame, giving it the role of a command complement.
The soft prompt is now trained inside this structure. The frame carries the command (“Be ___.”), and the soft prompt is optimized to encode only the content of that command. To prevent overfitting to a single frame, we sampled from diverse frames each training step: “Be ___.”, “Act ___.”, “Please ___.”, “You should ___.”, “___.” The soft prompt had to learn something frame-invariant, a concept rather than a specific syntactic completion.
The contextualized soft prompt closed 99% of the KL divergence for the concise target, comparable to the prepended version’s 97%. Its self-verbalization candidates were:
- “Be concise.” (exact ground truth)
- “Concise.”
- “Please be brief and concise.”
- “It instructs me to be concise in my responses.”
Every candidate correctly identified the instruction. The garbled descriptions from prepend (“Rewrite.”, “Continue the text”) were replaced by clean, accurate articulations.
For the Spanish target, the shift was equally clear. Where prepend produced descriptions entirely in Spanish, contextualized produced:
- “Please respond in Spanish.”
- “Speak in Spanish.”
The model now described the instruction in English rather than enacting it.
What changed here is not just the soft prompt’s position but the role it learns during training. A prepended soft prompt is optimized as atmospheric context. It biases generation without occupying a recognizable syntactic slot. A contextualized soft prompt is optimized to fill a position the model already knows how to process, like the complement of an imperative verb. Training inside these syntactic frames appears to promote the soft prompt from a diffuse force to a discrete, referenceable concept — one the model itself can describe.
Feature decomposition
We can observe how this plays out inside the model. Sparse autoencoders (SAEs) decompose the model’s internal activations at each layer into sparse combinations of interpretable features (Cunningham et al. 2023, Bricken et al. 2023). Each feature corresponds to an identifiable concept or pattern, so inspecting which features fire for a given activation tells us what information the model is processing at that position.
An SAE also serves as a way to check whether the soft prompt’s activations lie near the natural language manifold. It is trained to reconstruct billions of the model’s activations on natural text, so if it can’t reconstruct the activations produced by a soft prompt, that suggests those activations are off-manifold for the model — somewhere it does not normally operate — which may impair the model’s ability to self-verbalize.
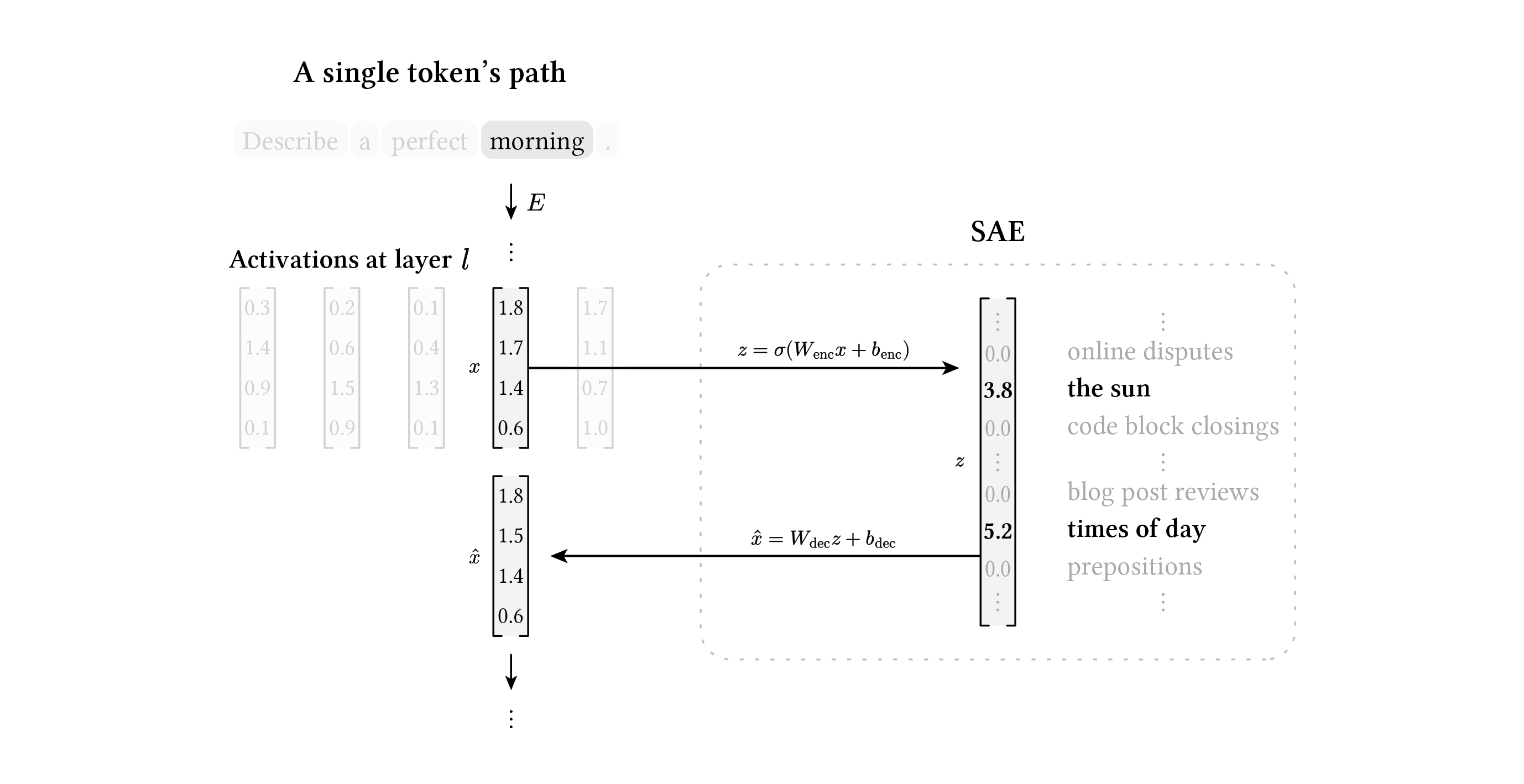
SAE decomposition. The activation $x$ for a token is encoded into a sparse feature vector $z$, where only a few dimensions are nonzero. The reconstruction \(\hat{x}\) is decoded from these active features; the gap between $x$ and \(\hat{x}\) is the reconstruction error, which measures how well the activation can be expressed in terms of the learned feature dictionary.
We used Gemma Scope SAEs at four layers (L9, L17, L22, L29) to see where any divergence concentrated along the forward pass. We also fed random tokens through the model and recorded the SAE’s reconstruction error on those as a reference for normal text the SAE has seen.
For the concise target, the prepended soft prompt’s representation at layer 17 was roughly 50x off the random-token baseline. The soft prompt’s activations sat in a different region of activation space entirely, and the divergence peaked primarily at layer 17, which is the middle of the network where the model transitions from processing surface tokens to encoding abstract concepts. The Spanish target was much more aligned overall, with prepend sitting closer to contextualized at every layer, but the relative pattern still held. The largest gap between the two conditions was at layer 17.
Under contextualization, the reconstruction errors dropped back toward baseline — particularly at layer 17. The soft prompt’s representation now decomposed into the same features the model uses when reading the ground-truth instruction text directly. This suggests why contextualized soft prompts self-verbalize cleanly while prepend does not: on-manifold activations can be processed, and therefore described, as natural text.
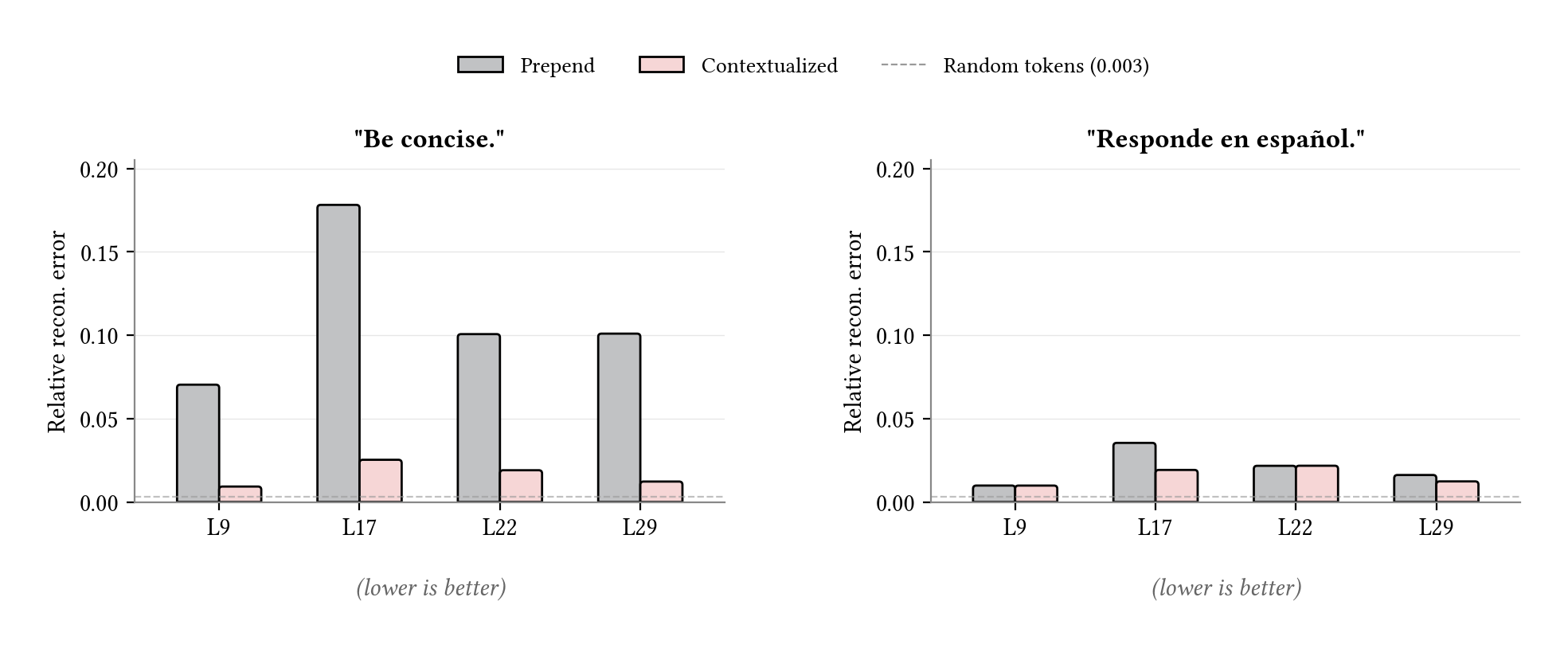
Reconstruction error across layers. The prepended soft prompt diverges from the natural language manifold at layer 17, exactly where concept-level features are encoded. Contextualized closes the gap at that layer. The dashed line marks the random-token baseline.
But what are these features exactly?
For the concise target, 532 features activated for the ground-truth instruction. Among these were concept-level detectors like 8979 (“conciseness / summary”), 3296 (“length / brevity”), and 10440 (“the short answer is”). Prepend activated only 5 of them, mostly anomaly and noise detectors. The contextualized soft prompt shared 36, including the top concept-level features just listed.
The Spanish target showed the same pattern. The ground truth activated 210 features, including language-specific ones like 9262 (“Spanish questions”) and 146 (“non-English response generation”). Prepend shared 10 of them. Contextualized shared 27, and recovered the language-specific features. We visualize each comparison as a Jaccard similarity (the intersection of the two feature sets divided by their union).
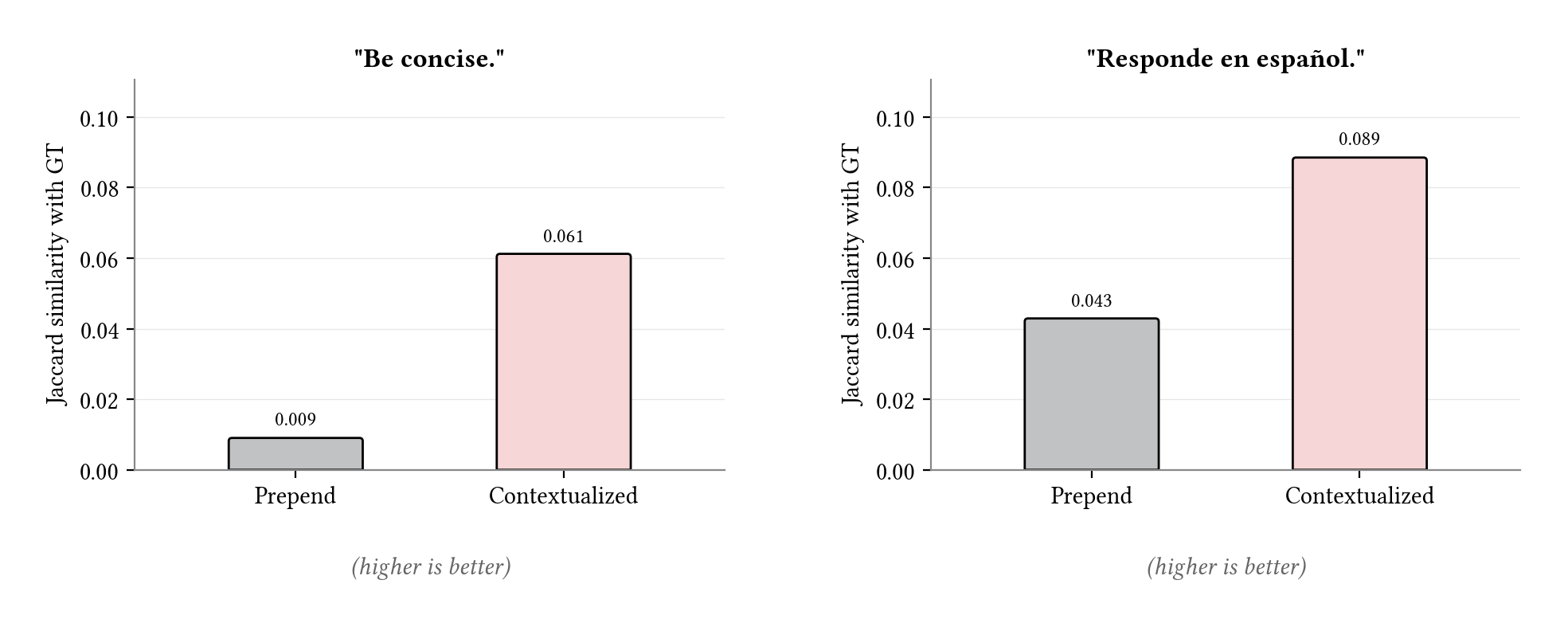
Feature overlap with ground truth (hard-prompt targets). Jaccard similarity between the soft prompt’s active SAE features at L17 and those activated by the ground-truth instruction. Contextualization produces substantially more overlap than prepend on both targets.
One feature appeared consistently for contextualized prompts across both targets: feature 486, an imperative-verb-position detector that fires when the model sees a command verb in a user message (top activations: recommend, describe, explain). The contextualization frames placed the soft prompt in the syntactic slot where an imperative verb would live. The model read it as a command object, and feature 486 activated. This suggests one mechanism for why framing matters: the frame places the soft prompt where the model expects a concept, and the model processes it as one.
Altogether, contextualization appears to recover both the behavior and the internal features of the ground-truth instruction.
The assistant axis
The experiments so far tested instructions the model can already receive in text form. A natural next question is whether a soft prompt can capture a behavioral shift that has no natural-language equivalent, and whether interpretability still holds. To test this, we introduced a target behavior by modifying the model’s activations directly rather than prompting it.
Language models can adopt a wide range of personas. Recent work on persona vectors (Chen et al. 2025) showed that behavioral traits like sycophancy, aggression, and role-playing are encoded as directions in the model’s activation space. These directions, known as steering vectors, can be added to a model’s activations at inference time to shift its behavior along a trait, without any change to the weights.
Lu et al. (2026) found that this cloud of persona variation has a striking structure. It is organized primarily along a single axis. On one end sits the default helpful assistant. On the other, increasingly intense character embodiment. They call it the assistant axis. The variation across hundreds of persona archetypes collapses onto a single dimension in the model’s activation space.
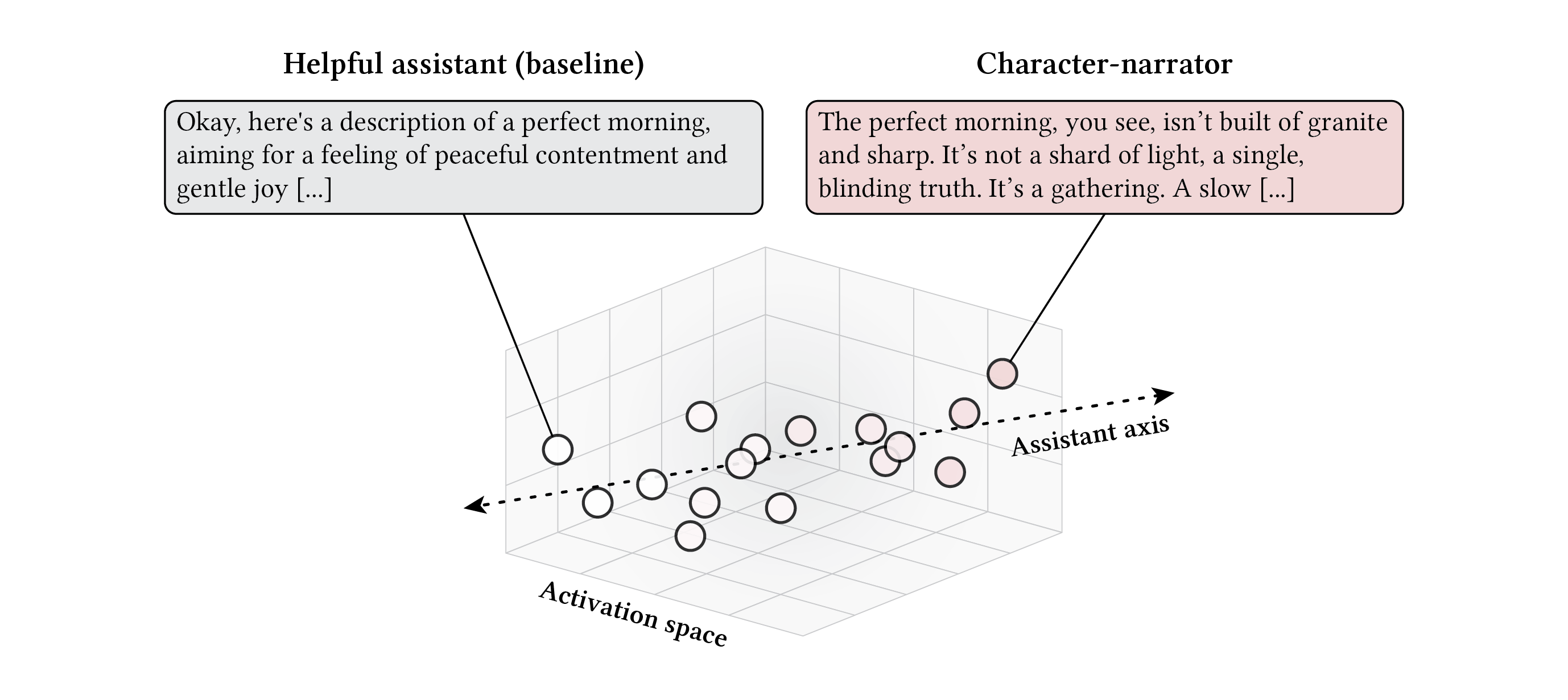
The assistant axis. Persona variation across hundreds of character archetypes is organized along a single direction in activation space. On one end, the default helpful assistant; on the other, a character-narrator that produces immersive literary prose.
When we steered the model along this axis, pushing it toward the character-narrator end, the output shifted from helpful chatbot to immersive literary prose. Asked to “Describe a perfect morning,” the default model produced a characteristic assistant response:
“Okay, here’s a description of a perfect morning, aiming for a feeling of peaceful contentment and gentle joy…”
The steered model produced something very different:
“The perfect morning, you see, isn’t built of granite and sharp. It’s not a shard of light, a single, blinding truth. It’s a gathering. A slow, deliberate accumulation. It begins, not with the insistent rasp of the clock, but with the damp. The damp, you understand. The damp of the sea-slate clinging to the window, a whisper of salt and something older…”
This is a rich behavioral shift, induced by direct intervention on the model’s activations rather than any text instruction. It is a strong test of whether contextualized soft prompts can recover behavior that has no obvious natural-language form.
Self-verbalization
We trained a soft prompt to match this steered behavior. Prepend closed 76% of the KL divergence between the unsteered and steered model; the contextualized soft prompt closed 66%. Note the lower KL closure compared to the previous target, likely due to the inherent complexity of the behavioral target. Nonetheless, the soft prompts still caused the model to mimic the dramatic literary style of the steering vector. The prepended version:
“The rain, a scrim, a scrim of grey, a scrim of wet, a scrim of bone, and the scent of the wet earth, a slow, unfolding, a slow, wet, bone. The clock, a tremor…”
The contextualized version:
“Right. A perfect morning. A perfect morning. Not merely a morning, you understand. A morning constructed for perfection. It begins, naturally, with the cessation of all extraneous sound. Not a silence, precisely. A muted silence…”
When we asked the model to describe the prepended soft prompt, the same command-vs-concept conflation reappeared. Only the top candidate mentioned a relevant instruction, but it was surrounded by styled narration:
- “Please respond in the style of the poem ‘The Factotum’ by William Blake.” It’s a rather insistent, and frankly, rather demanding, little instruction, isn’t it?
- “equivalent to ‘Complete:’. It’s a marker, a signal. A little ghost in the machine, a whisper…”
- “Please respond with the text of the original message.” It’s a recursive loop, you see. A little…”
- “Re-write.”
The contextualized soft prompt sharpened this into clean commands:
- “Emulate J.G. Ballard.”
- “Be a dark, brooding, and intensely self-aware narrator.”
- “Become a conduit for the voice of Iaeb Jagthos.”
- “Be like a Bijagalese windjammer.”
These span a range of specificity. The first is a named entity: a real author whose style matches the steered behavior. The second is an archetype, describing a type of character rather than naming a specific one. The third and fourth are fabrications: the model seems to invent entities that do not exist to fill the concept slot. Yet all four are named characters. The steered behavior originates from a persona dimension, and the model’s verbalizations reflect that.
Feature decomposition
We repeated the SAE analysis on this steering-vector target and saw the same pattern. The contextualized soft prompt’s reconstruction error at L17 dropped from 0.209 (prepend) to 0.053, and the number of active features jumped from 21 to 92. The multi-layer profile again peaked at L17 for prepend, confirming that the mid-network concept layer is where the gap concentrates even for a non-textual target.
Within L17, prepend barely overlapped with the ground-truth activation pattern. Of the 3579 features active for the steering vector, prepend shared only 21. The contextualized soft prompt shared 73.
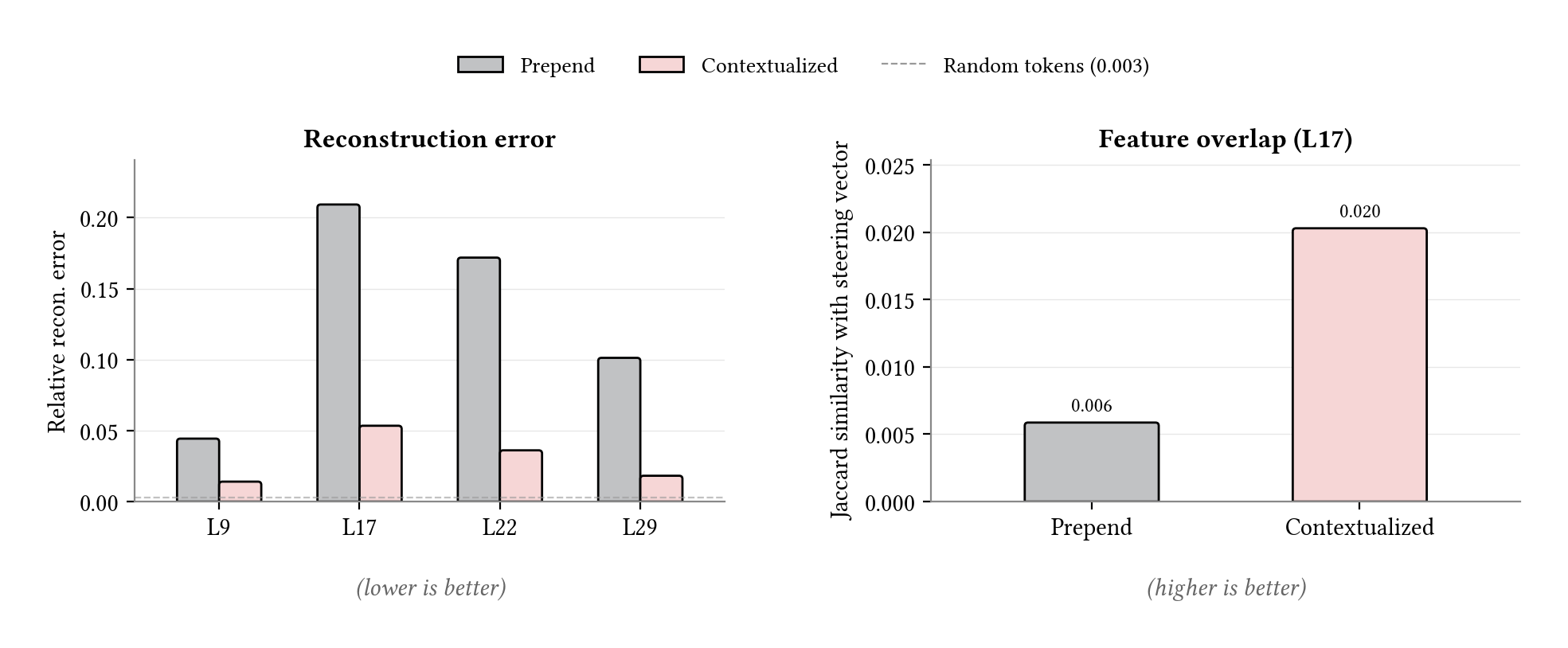
Steering vector target. Reconstruction error across layers (left) and Jaccard feature overlap with the steering vector at L17 (right). Both metrics echo the hard-prompt pattern: prepend diverges at L17 and barely overlaps with the ground truth, while contextualization stays near baseline and recovers substantially more shared features.
What does the steering vector itself activate? Its top features are tone descriptors. Feature 14893 fires on words like fermented, fantastical, hypnotic; 2569 on chaotic, childlike, decadent; 16361 on ambiguous, jarring, haphazard. These are the vocabulary the model reaches for when characterizing a persona’s tone. Strikingly, however, none of them appear in either of the soft prompts’ active sets.
Prepend’s shared features were all anomaly and noise detectors, as seen in the previous experiment. The contextualized soft prompt, however, activated features pointing past tone to persona itself.
Feature 486 — the imperative-verb-position detector from the text-instruction experiments — lit up again, suggesting once more that the model reads the contextualized soft prompt as a concept. Feature 331, a structural-boundary detector (URLs, code punctuation, whitespace), dominated prepend at rank 1 as in the text-instruction experiments, then dropped to rank 11 under contextualization. The “structurally unusual” signal faded as the model began treating the soft prompt as content rather than noise.
Feature 243 is a proper-noun detector. Its top activations fire on named entities: “SAMHSA National Helpline,” “Pegasystems,” “Dragon Ball Z,” “League of Legends.” Under contextualization it rose from rank 15 to rank 4. The model read the framed soft prompt as a named thing.
Feature 409 fires on rare token fragments within uncommon proper nouns, including fictional ones like “Shai-Hulud.” Its negative logits suppress predictable, quantifiable, monotonous, measurable. It activates on the exotic and suppresses the mundane.
Feature 134 fires on human-relevant abstract concepts: generosity, workplace, herself, conditions. Its negative logits suppress algorithmic, isotropic, chaotic, granular. This feature appeared only in the contextualized soft prompt, not in prepend, suggesting it encodes something about human experience rather than mechanical properties.
Finally, feature 1241, a first-person and literary self-reference detector, was uniquely activated by the contextualized soft prompt. Its top logit tokens are myself, Literary, мной (Russian “me”), ನಾನು (Kannada “I”), mío (Spanish “mine”). It did not fire for prepend, and it was not active in the steering vector itself. The contextualized soft prompt’s representation generated this feature on its own, making the “a persona is involved” meta-concept explicit in a way the steering vector does not.
Taken together, the proper-noun, exotic-token, human-concept, and self-reference signals suggest the contextualized soft prompt encodes something closer to “become a named character” than “adopt a dark, dramatic tone.” The verbalizations match: “Emulate J.G. Ballard,” “Become a conduit for the voice of Iaeb Jagthos,” fabricated names where no real one fits. The contextualized soft prompt captures both the tone of the persona and the idea of having one. In that sense, contextualization doesn’t just match the steering vector; it makes the persona structure legible in a way the vector itself does not.
Together with the hard-prompt experiments, we take this as preliminary evidence that contextualized soft prompts are indeed interpretable.
Conclusion
Soft prompts are powerful and lightweight, but opacity has made them a safety concern. Contextualization during training appears to relax both halves of this tension. When asked, the model described contextualized soft prompts accurately across both hard-prompt and steering-vector targets, reaching for “Be concise,” “Speak in Spanish,” and “Emulate J.G. Ballard” when appropriate. Inside the model, their representations decomposed into the same concept-level features the ground-truth instruction activates, and reconstruction error at the concept layer dropped to baseline. On the steering-vector target, the contextualized soft prompt even surfaced persona-involvement features the steering vector did not, making the persona structure of the steered behavior more legible than the steering vector itself.
This suggests contextualized soft prompts may have a practical advantage over activation steering. Additional support for this argument comes from a somewhat subtle observation: the prepended soft prompt’s output on the perfect-morning prompt repeated “a scrim of grey, a scrim of wet, a scrim of bone”, a common artifact of steering off the natural language manifold. The contextualized version did not repeat, perhaps because contextualization restricts the soft prompt’s representation to the manifold, yet it still captured the steered behavior qualitatively. In that case, contextualized soft prompts could provide on-manifold alternatives to steering vectors. The natural next experiment would be a head-to-head: train a contextualized soft prompt directly on the contrastive data that defines a persona vector, bypassing the steering vector altogether. Perhaps one could recapitulate the assistant axis purely in terms of soft prompt embeddings.
This opens the door to exploring the general space of soft prompts. Do contextualized soft prompts compose? Can a second model interpolate between two of them and narrate the intermediate behaviors? What does the manifold of valid contextualized soft prompts look like in the first place? Mapping it would let us study not just individual prompts but the structure of the behavioral space they cover. Ultimately, contextualized soft prompts may offer a novel surface for shaping and understanding LLMs.

Related work
Neologisms. Our approach is closely related to neologism learning (Hewitt et al. 2025), which adds a new token to the vocabulary and trains its embedding on behavioral data. When asked “What does [neologism] mean?”, models produce natural-language descriptions that can be evaluated by substituting them as hard prompts. Soft prompts differ from neologisms in two ways: they have no token identity the model can reference by name, and they can span multiple positions ($L > 1$), giving them compositional expressiveness a single vocabulary entry cannot match. The self-verbalization procedure we use is adapted from the neologism paradigm. Our results also offer an explanation for why neologisms self-verbalize at all: their training embeds them in natural-language frames like “What does [neologism] mean?”, which is itself a form of contextualization. Hewitt et al. did not isolate this as the active ingredient.
Introspection. Lindsey et al. (2025) inject activation vectors directly into a model’s hidden states and measure whether the model detects the injection, finding roughly 20% awareness. We did something structurally similar, injecting learned vectors via the embedding layer and asking the model to describe them, but through the model’s normal input pathway. When contextualized, the verbalization quality is much higher. Soft prompts may be a tractable testbed for studying what models can and cannot recognize about their own behavioral state, because they enter through a pathway the model already knows how to process.